Python Tweets Program Using JSON
In this part of the project, we will take a collection of tweets from my Twitter account and perform some basic natural language processing tasks. The file is ‘jbh_tweets.txt’and can be downloaded here.
The file is in json format and consists of a list containing tweets. Each tweet is actually a dictionary with two keys,’id’and’tweet_text’:
‘id’: the Twitter ID number for each tweet.
‘tweet_text’: a list containing the tokenized text of each tweet. The text was processed using NLTK and a Twitter-specific tokenizer. All URLs were stripped out and replaced with ‘URL’. Since it appears daily, all instances of ‘The Joe Bob Hester Daily is out!’ were replaced with ‘JBHdaily’. All instances of ‘RT @someuser’ were retained in that format as a single token rather than being split into ‘RT’ and ‘@someuser’. All characters other than ‘URL’, ‘RT @’, and ‘JBHdaily’ were converted to lower-case.
The content of the file looks like this:
[{“id”: “551427775824142336”, “tweet_text”: [“JBHdaily”, “URL”]}, {“id”: “551065361987420161”, “tweet_text”: [“JBHdaily”, “URL”, “stories”, “via”, “@stromeao”, “@hardrockhotellv”, “@jzspeaks”]}, … DELETED TO SAVE SPACE … ]
To access the file you will need to use the json module:
import json
fin = open(‘jbh_tweets.txt’, ‘r’)
tweets = json.load(fin)
Because tweets is a list, you can access the text of any tweet by using a list index to access the tweet and a dictionary key to access the text:
The text of the first tweet in the file:
>>> tweets[0][‘tweet_text’]
[‘JBHdaily’, ‘URL’]
The text of the second tweet in the file:
>>> tweets[1][‘tweet_text’]
[‘JBHdaily’, ‘URL’, ‘stories’, ‘via’, ‘@stromeao’, ‘@hardrockhotellv’, ‘@jzspeaks’]
So, if you needed to loop through all the tweets in the file, you could do it like this:
for x in range(len(tweets)):
tweets[x] # to access entire dictionary of tweet
tweets[x][‘id’] # to access ID number
tweets[x][‘tweet_text’] # to access tweet text
And if you needed to loop through each token in each tweet, you could do it like this:
for x in range(len(tweets)):
for token in tweets[x][‘tweet_text’]:
For this portion of the project, write a single Python script that prints answers to the questions. You can enter your answers to check their accuracy. Then, paste the script in the space below the questions (Be sure to use the “Paste as plain text” button). Note: Your Python script must work correctly in order to receive credit for the answers
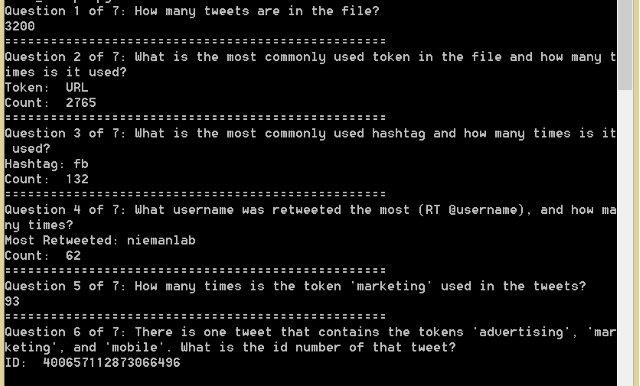
How many tweets are in the file? |
||
What is the most commonly used token in the file and how many times is it used? (Do not include quote marks in your response.) |
||
What is the most commonly used hashtag and how many times is it used? (Do not use the ‘#’ symbol in your response.) |
||
What username was retweeted the most (RT @username), and how many times? (Do not include the ‘@’ in your response.) |
||
How many times is the token ‘marketing’ used in the tweets? |
||
There is one tweet that contains the tokens ‘advertising’, ‘marketing’, and ‘mobile’. What is the id number of that tweet? |
| Question 7 of 7 | 0.0 Points |
Enter your script here. Be sure to use the “Paste as plain text” button above to preserve your formatting/indentions.
- File Format: Python .py
- Version: 3.5
- Lines of Code: 58